Day 4Lecture Notes
Lectures 3 & 4
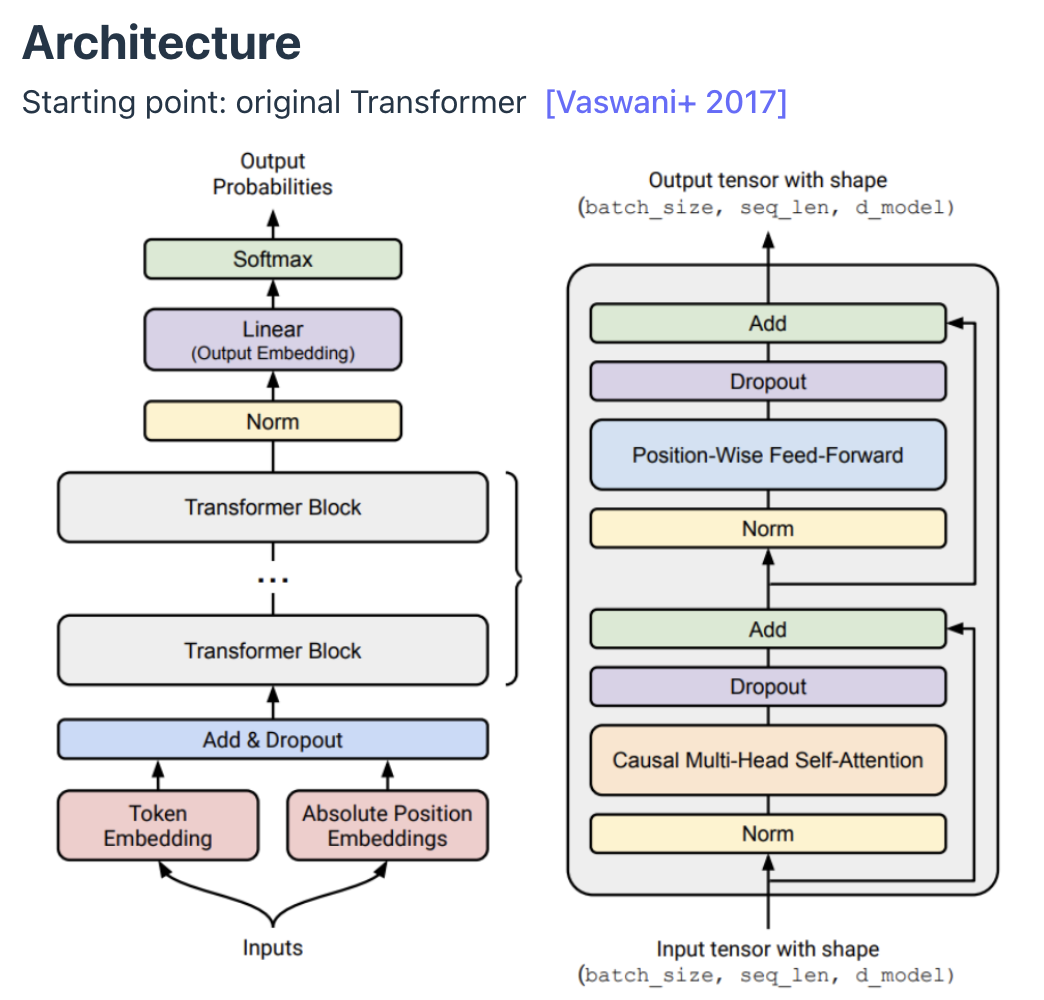
Pre-Norm works better, even without warmup. Also doesn't need gradient attenuation Normalization operation optimization is important because of memory movement not just FLOPS Activations: GeLU - CDF of gaussian * ReLU, makes it more differentiable Gated entry wise (using the X) the inner part of the MLP GeGLU is gated version GeLU Gated units create slightly…
7h